
栈(Stack)
1.概念
栈又称堆栈,是限制在表的一端进行插入和删除运算的线性表。
表中进行插入、删除操作的一端称为栈顶(top)。 栈顶保存的元素称为栈顶元素。 表的另一端称为栈底(bottom)。 当栈中没有元素时称为空栈。 向一个栈中插入元素称为进栈或入栈或压栈(push)。插入的元素是当前最新的。 从一个栈中删除元素称为出栈或退栈或弹栈(pop)。删除的元素是当前最新的。 由于栈的插入和删除仅在栈顶进行,后进栈的元素必定先出栈,所以把堆栈称为后进先出表(Last In First Out,LIFO)。 当栈满时进栈运算称为上溢;当栈空时出栈运算称为下溢。2.ADT定义
基本操作和ADT定义如下:
ADT Stack{ 数据对象:D={ai|ai∈element,i=1,2,3……,n,n≥0} 数据关系:R={ |ai-1,ai∈D,约定an端为栈顶,a1端为栈底} 基本操作: init(int s); //构造一个空栈s clear(); //清空栈 isEmpty(); //判断堆栈是否为空 isFull(); //判断栈是否满。 peek(); //获取栈顶元素但不出栈 push(Object o); //元素o入栈 pop(); //栈顶元素出栈 getSize(); //获取元素个数。}ADT Stack 3.分类
堆栈的存储结构有顺序存储结构和链式存储结构两种。
在顺序存储结构中要考虑堆栈的上溢;在链式存储结构中要考虑堆栈的下溢。 堆栈上溢是一种出错状态,应该设法避免它;堆栈下溢可能是正常现象,通常下溢用来作为程序控制转移的条件。 就线性表而言,实现栈的方法有很多,这里着重介绍顺序栈(arrary based stack)和链式栈(linked stack)。1>顺序栈
顺序栈(arrary based stack)的实现从本质上讲,就是顺序线性表实现的简化。
如果用数组来实现,唯一要确定的是使用哪一端来表示栈顶。 如果使用数组的其实位置来作为栈顶,那么在删除和插入的时候会有很大的时间消耗,因为平移元素。 如果使用素组的尾端来作为栈顶,那么就不需要移动元素了。①基本运算
堆栈的运算主要考虑入栈和出栈的算法。
入栈时需要考虑的操作步骤是堆栈初始化,然后判断堆栈是否为满,如果不满,则可以插入元素。 出栈时,需要考虑的步骤是判断堆栈是否为空,如果不空,删除元素,出栈之前,保存栈顶元素。②顺序栈共享空间
堆栈顺序存储时,为避免上溢,需要首先分配较大空间,但这容易造成大量的空间浪费。所以当使用两个栈时,可以将两个栈的栈底设在向量空间的两端,让两个栈各自向中间靠拢,使空间得以共享。逻辑图如下:
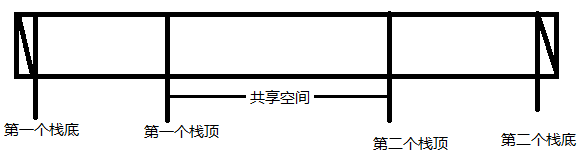
具体实现方法
利用一个数组来存储两个堆栈,每个栈各自的断点向中间延伸。③实现
利用数组实现一个顺序栈。
/** * 使用数组实现堆栈 * @author 星汉 * */public class ListStack { private Object[] elements;//数组容器 private int size;//元素个数 /** * 默认大小为32的堆栈 */ public ListStack() { this.elements=new Object[32]; this.size=0; } /** * 清空栈 * @return 成功返回true */ public boolean clear() { for(int i=size-1;i>=0;i--,size--) { elements[i]=null; } return size<=0; } /** * 判断栈是否为空 * @return 为空返回true */ public boolean isEmpty() { return size==0; } /** * 判断是否满栈 * @return 栈满返回true */ public boolean isFull() { return size==elements.length; } /** * 获取栈顶元素,但不删除栈顶元素 * @return object 栈顶元素 */ public Object peek() { if(size!=0) { return elements[size-1]; } return null; } /** * 入栈 * @param o 入栈元素 */ public void push(Object o) { if(size 0) { Object tmp = elements[size-1]; elements[size-1]=null; size--; return tmp; }else { System.out.println("下溢"); return null; } } /** * 返回栈中元素个数 * @return */ public int getSize() { return size; }} 2>链式栈
堆栈的链式存储称为链栈,即采用链表作为存储结构实现的栈。链式栈的基本运算同顺序栈。它是对链表实现的简单化。
使用单向链表实现的栈只能对表头进行操作,因为不能反向查找。3>顺序栈和链式栈对比
实现顺序栈和链式栈都需要常数时间。
顺序堆栈初始时,需要说明一个固定的长度,当堆栈不够满时,会造成空间浪费。 链式栈的长度可变,不需要预先设定,相对比较节省空间,但是每个结点中设置一个指针域会产生结构开销。 顺序栈可以实现共享空间。 链式栈一般不用。4.应用
堆栈的应用例子比较多,但比较典型的是数制的转换、表达式的计算、转换问题和递归问题。
1>数制转换
数制转换的基本原理:
N mod d的值是余数,余数作为转化后的值,用N div d的商再作为N的值,再求余数,依次类推,直到商数为零。最后所得的余数反向输出,就是需要的结果。 由上述原理可以看出,这个过程恰好满足栈的运算规则:先进后出。所以可以使用堆栈实现数制的转换。/** * 数制转换 * @author 星汉 * */public class TransportNum { public static void main(String[] args) { ListStack ls=new ListStack();//利用上面实现的栈 int n=20;//未知数 int remainder=0;//余数 int d=2;//进制数 while(n!=0) { remainder=n%d; n=n/d; ls.push(remainder);//将余数入栈 } while(!ls.isEmpty()){ System.out.print(ls.pop()); } }} 2>表达式的转换
表达式一般有中缀表达式、后缀表达式和前缀表达式3种表现形式。现实生活中使用的是中缀表达式,计算机内存储表达式时一般采用后缀或前缀表达式。
一个表达式通常由操作数、运算符及分隔符所构成。 中缀表达式就是将运算符放在操作数中间,例如:a+b*c 由于运算符有优先级,所以在计算机内部使用中缀表达式是非常不方便的。为了方便处理起见,一般需要将中缀表达式利用堆栈转换成为计算机比较容易识别的前缀表达式或者后缀表达式。 例如:前缀表达式:+a*bc 后缀表达式:abc*+ 其转换过程按照优先级转换,运算符的优先级顺序表如下图: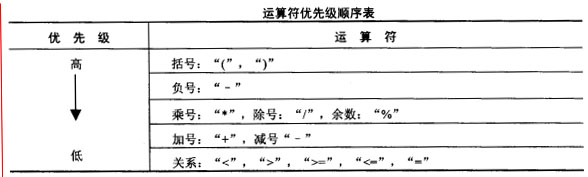
以中缀表达式a/(b-c)为例,演示一下中缀表达式转换为前缀表达式的具体步骤:
第一步:先处理优先级高的,括号内将(b-c)转换为(-bc)。 第二步:将除号进行处理为/a,整个表达式为/a(-bc)。 第三步:消除括号为/a-bc,就是将中缀表达式转为前缀表达式。利用堆栈处理中缀表达式的步骤如下:
第一步:设置两个堆栈,一个操作数堆栈和一个运算符堆栈。 第二步:初始时为空,读取表达式时,只要督导操作数,将操作数压入操作数栈。 第三步:当读到运算符时将新运算符和栈顶运算符的优先级比较,如果新运算符的优先级高于栈顶运算符的优先级,将新运算符压入运算符堆栈;否则取出栈顶的运算符,同时取出操作数堆栈中的两个操作数进行计算,计算结果压入操作数堆栈。中缀表达式的计算需要使用两个堆栈,并且计算比较频繁,而后缀或前缀表达式的实现只需要一个堆栈。
将中缀表达式转换为后缀表达式,转换原则如下: 第一:从左至右读取一个中缀表达式。 第二:若读取的是操作数,则直接输出。 第三:若读取的是运算符,分三种情况: 1.该运算符为左括号“(”,则直接存入堆栈。 2.该运算符为右括号“)”,则输出堆栈的运算符,直接取出左括号为止。 3.该运算符为费括号运算符,则与堆栈顶端的运算符做优先权比较,若堆栈顶端运算符高或者相等,则直接存入栈;若较栈顶端的运算符低,则输出堆栈中的运算符。 第四:当表达式已经读取完成,而堆栈中尚有运算符时,则依次序取出运算符,知道堆栈为空,由此得到的结果就是中缀表达式转换成的后缀表达式。3>递归
递归问题实际上是程序或函数重复调用自己,并传入不同的变量来执行一种程序。
递归程序编写虽然简单,但在时间和空间上往往是不节省的。 递归是一种比较好的程序设计方法,比较典型的范例是汉内塔、数学上的阶乘以及最大公因子等问题。下面仅以阶乘问题来说明递归。 阶乘定义为:if n!=1 n=0 if n!=n*(n-1)! n>1 程序设计方法: 第一递归结束条件,当阶乘小于或等于1时,返回1。 第二递归执行部分,当阶乘大于1时,返回n!=n*(n-1)!。 实现: public static int recursion(int n) { if(n<=1) { return 1; }else { return n*recursion(n-1); }} 4>递归的非递归实现
在递归程序中,主要就是一个堆栈的变化过程,程序执行过程中,堆栈是由系统自动实现的,但是我们应该能够将递归的程序变为非递归的实现。
非递归程序中,需要了解的是什么数据需要或什么时间压入堆栈,什么数据需要或在什么时候出堆栈。 例如上例中的阶乘问题,使用非递归实现,可以考虑实现将不同的n压入堆栈,每次减1,最后能够实现0的阶乘的计算,然后返回,知道堆栈为空为止。 public static void main(String[] args) { //使用之前实现的链式堆栈 LinkedStack ls=new LinkedStack(); int num=10; while(num!=0) { ls.push(num); num--; } int product=1; while(!ls.isEmpty()) { product*=(int)ls.pop(); } System.out.println(product);} 上一篇:
下一篇: